Predictable Patterns & PII Leakages: Using AI to mass leak data
Ever spent ages looking for keys that were right in front of you? Security research feels the same - you know the bug is there, hiding in plain sight.
Here's the thing about bug hunting: it's rarely about finding novel zero-days. More often, it's about spotting those subtle patterns that everyone else missed. The challenge? Testing hundreds of variations quickly enough to find that one edge case that breaks everything.
TL;DR
Let me share how AI helped uncover vulnerabilities in a document ID system, revealing sensitive files across an entire platform. The bug itself wasn’t especially complex, but using AI allowed us to analyse patterns at scale—something that would have been time-consuming and likely overlooked if done manually.
The Initial Discovery
Every good bug story starts with that moment of "huh, that's weird." Mine started with this beauty:
672f7aacd9538fef01d44dd1721fe5767b5b1d3553672-181Just another document ID from an upload system, right? But something was off—it was always 49 characters long, not the 32-character length you'd expect from an MD5 hash, nor did it match SHA1 or any standard hash algorithm. And with each upload, it changed completely, even for identical files.

First Attempts
The pattern for the ID seemed interesting to go after as this service was not mapping the users authorisation cookie to the document ID so if it's broken, we could potentially access other users document on the platform.
TIP
🔍 Hunter's Tip #1: Pay attention to lengths that don't match common standards. They often hint at custom implementations, which can be a goldmine for security issues.
The "It Must Be Simple" Phase:
- Maybe it's just Base64? Nope.
- It has got to be MD5? Nope.
- What about hex encoding? Nada.
- What about sha256? Zilch.
But here's where it got interesting. Identical files, uploaded seconds apart, produced IDs that were different... except for:
- The first few characters that seemed similar with some pattern
- Last few digits that seemed sequential
TIP
🔍 Hunter's Tip #2: When testing file uploads, always try identical files in rapid succession. The differences (or similarities) in the generated IDs can tell you a lot about the underlying system.
Leveraging AI for Pattern Analysis
This is where AI LLMs changes the game. Instead of manually analysing patterns, I generated 100 IDs and fed them to Anthropic's Claude 3.5 for analysis.
Me: "Here are 100 document IDs. Can you spot any patterns, particularly around timestamps?"
Claude: "The first 8 characters appear to be hex timestamps. Look at these consecutive uploads..."Indeed, in seconds we had our first breakthrough:
pattern = {
'timestamp': id[:8], # Hex timestamp
'random': id[8:45], # Unknown portion
'sequence': id[46:] # Sequential number
}TIP
🔍 Hunter's Tip #3: Use AI not just for coding, but for pattern recognition. It can spot regularities in data that might take hours to notice manually.
Taking this new information through Burp Sequencer analysis suggested the middle portion was sufficiently random. The challenge was that identical input data produced different outputs, except for the timestamp and sequence number.
Breaking Down the Algorithm

The middle section (37 characters) was the interesting bit as we already understood the role of the other parts.
However, it's:
- Too long for MD5
- Too short for SHA1
- Too odd for a GUID
- Too random to be client-based
It also could not be based on a fixed value like our IP address, or the server MAC address as that static datapoint would not change between each request to explain the randomness of the output.
I leveraged an LLM to generate test cases for various hashing combinations to rule out anything obvious to explain the padding or hashing input, with the assumption the sequence is used for the input:
test_strings = [
# Basic combinations
timestamp_hex + sequence,
sequence + timestamp_hex,
# With datetime variations
timestamp_str + sequence,
unix_timestamp + sequence,
# With the trailing 5 digits
timestamp_hex + full_hash[-5:],
sequence + full_hash[-5:],
# Reversed combinations
sequence[::-1] + timestamp_hex,
timestamp_hex[::-1] + sequence,
# Mixed formats
hex(int(sequence))[2:] + timestamp_hex,
timestamp_hex + hex(int(sequence))[2:],
# With different separators
f"{timestamp_hex}-{sequence}",
f"{timestamp_hex}_{sequence}",
f"{timestamp_hex}:{sequence}"
]No luck there and this is starting to get too complex for a likely basic algorithm.
The Breakthrough: Phone a friend
I was close to giving up but something kept nagging at me. That's when I reached out to a great friend and fellow hunter Lupin, a true master at quickly validating ideas.
This is crucial in security research - knowing when to get a second pair of eyes. Sometimes you need someone to either tell you you're chasing dead ends or push you to dig deeper.
My pitch was word for word the app feels a little dodgy, using PHP and the iteration at the end makes me think this is not well thought out so there has got to be simple explanation for the hashing algorithm.
TIP
🔍 Hunter's Tip #4: When stuck, verbalize your assumptions. Sometimes just explaining the problem to someone else reveals the solution.
We brainstormed on what the code could be doing
- Is it using a temp file name to generate the hash?
$hash = md5(__DIR__ . $filename . time()) . substr(uniqid(), 0, 5);- Is it using a salt?
$hash = md5($filename . time() . $salt) . generatePadding(5);- Is it a Unix timestamp to hash + some padding?
$hash = md5(time()) . random_bytes(5);- Is it a string timestamp to hash + some padding?
$hash = md5(date('Y-m-d H:i:s')) . bin2hex(random_bytes(5));Testing hash theories manually is like watching paint dry - technically possible, but life's too short. Enter AI as our pattern-matching accelerator.
Instead of grinding through each possibility, we fed our theories to an LLM, which translated them into some python permutations options and targeted hashcat commands so the theories can be validated n with ease.
Hashcat is a powerful tool for cracking hashes. It supports a wide range of algorithms and attack types, including brute force, dictionary, and rule-based attacks where you can provide it with input along with a mask to generate test cases for the missing piece of the puzzle.
The idea here was to generate a mask for the missing part of the hash and test it against the known parts.
One such LLM provided output worked like a charm. The system cracked it in < 1 seconds:
hashcat -m 0 -a 3 fef01d44dd1721fe5767b5b1d3553672 '672f7aac?h?h?h?h?h'Let's break this command down:
-m 0: "Hey hashcat, we're dealing with plain old MD5 here"
-a 3: "Use mask attack mode" (more on this in a second)
fef01d44dd1721fe5767b5b1d3553672: The mysterious middle section we're trying to crack
672f7aac?h?h?h?h?h: The magic mask patternThat last part is where it gets interesting. We're telling hashcat:
672f7aac: "We know these exact characters from the timestamp"
?h?h?h?h?h: "Then try every possible hex character for these 5 positions"What made this particularly elegant was the limited search space:
# Search space breakdown
characters = 16 # Hex characters (0-9, a-f)
positions = 5 # Padding length
combinations = 16^5 = 1,048,576On a modern GPU, that's less than a second of work. Running hashcat confirmed our theory:
fef01d44dd1721fe5767b5b1d3553672:672f7aacd9539
Session..........: hashcat
Status...........: Cracked
Hash.Mode........: 0 (MD5)
Hash.Target......: fef01d44dd1721fe5767b5b1d3553672
Time.Started.....: Sun Nov 10 17:39:07 2024 (0 secs)
Time.Estimated...: Sun Nov 10 17:39:07 2024 (0 secs)
Kernel.Feature...: Pure Kernel
Guess.Mask.......: 672f7aac?h?h?h?h?h [13]Understanding the Pattern
The algorithm was using a timestamp with a 5-character padding to generate an MD5 hash.
Initially, we expected the padding to be completely random - after all, that's usually the point of padding. After some brainstorming, we considered an interesting possibility: what if the timestamp was used as a seed twice in the hashing algorithm? Once when submitting the document and again when generating the ID.
The Double Timestamp Theory
I asked Claude to help analyse this theory, and it quickly confirmed a pattern:
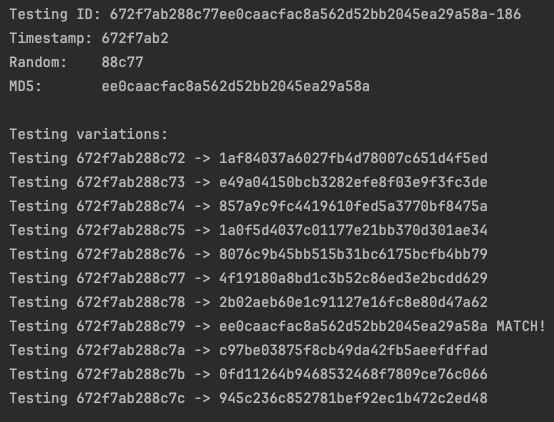
The seed we see in the document ID is off by just a few values from the seed we cracked to generate the 32 character hash:
Original Hash: 672f7aac d9538 fef01d44dd1721fe5767b5b1d3553672 -181Cracked input: timestamp + d95389 [incremented by 1 from d9538]
Cracked output: fef01d44dd1721fe5767b5b1d3553672
final Hash: timestamp + fef01d44dd1721fe5767b5b1d3553672 + 181This meant the output was always 1-5 values greater than the input likely due to the time difference between these operations:
Upload Time (t1) → Process Time (t2) → ID Generation (t3)
↓ ↓ ↓
First Hash ----→ MD5 + Padding ----→ Final IDThe "random" padding wasn't random at all - it seemed like a hash of the timestamp peeling away the complexity here further.
Impact
This vulnerability enables a classic sandwich attack:
- Upload a document and request its ID
- Wait briefly
- Request the ID again
- The timestamp difference reveals the timestamp and sequence number to work out the seed and download other user's documents.
Conclusion: LLMs and Bug Hunting
This experience highlighted how modern AI tools can accelerate the bug hunting process. While they don't replace human intuition and experience, they can:
- Quickly identify patterns in large datasets
- Generate comprehensive test cases
- Suggest implementation patterns
- Accelerate hypothesis testing
The future of security research lies in this synthesis of human intuition and AI-powered analysis. The tools augment our capabilities, but the core skills remain the same: curiosity, persistence, and the ability to spot patterns that don't quite fit.
Shoutouts
Lupin - For this fun collaboration and extensive feedback on the writeup
Note: All testing was conducted ethically with proper disclosure. No actual user data was accessed.